I asked a question on twitter on finding bad labels in training data that gave some interesting responses. One suggestion led me to this paper.

The paper has a method to find bad labels and they varify this method via mechanical turk. After doing their exercise they really list some hard facts.
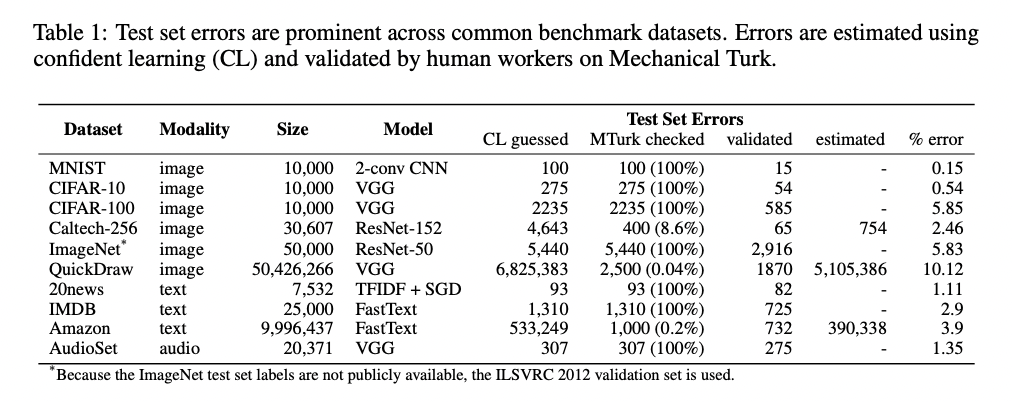
The QuickDraw dataset is especially worrying with a 10.12% error rate. Note, we’re talking about wrong labels in the test set here! That means that state-of-the-art results have been published based on these erroneous labels.
Label Errors
The effort in the paper eventually led to labelerrors.com project. It’s a website that lets you explore labels that are suspicious. It’s definitely worth a visit if you haven’t seen it yet
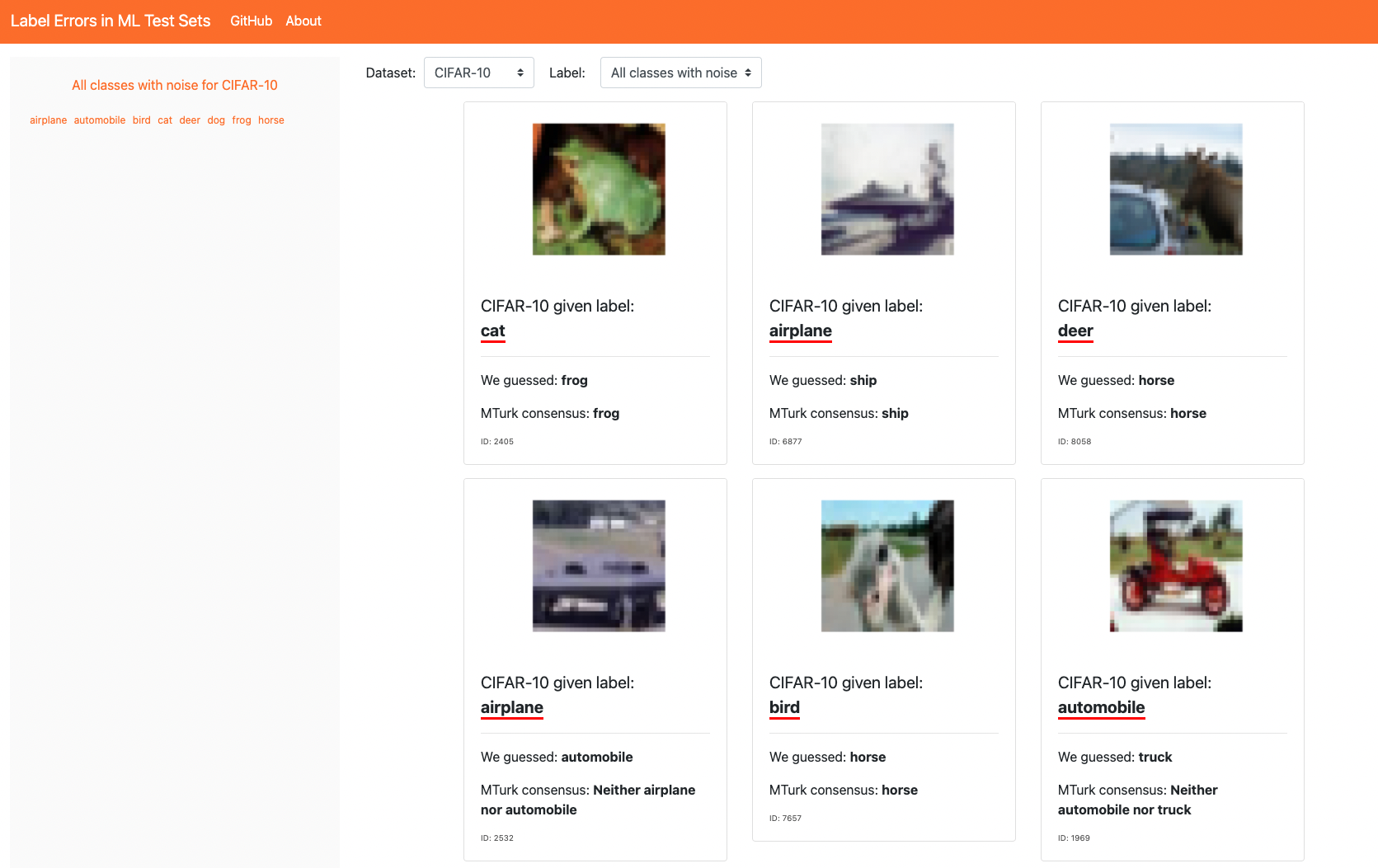
Finding Bad Examples
The way the bad examples are found are pretty interesting too. There’s more parts to the big picture but one part of their analysis revolves around analyzing the confusion matrix that the algorithm generates.
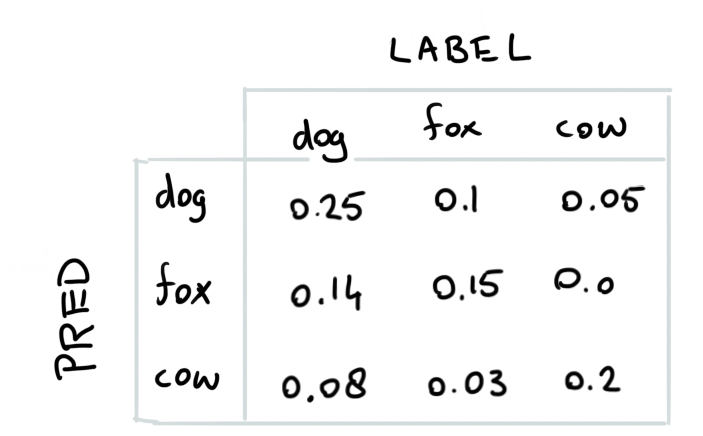
Given such a confusion matrix, we need to follow three steps.
- Use the numbers in the confusion matrix to estimate bad examples. Let’s say your data set has 100 examples then you can infer that there will be 10 foxes wrongly classified as dogs in our example.
- Mark the 10 images labeled dog with largest probability of belonging to class fox as label issues.
- Repeat for all non-diagonal entries in the matrix.
There’s some extra’s that I’m skipping here but the heuristic feels sensible. It’s a pretty simple avenue to consider too, so it’s certainly worth the exercise! If you’re interested in giving this idea a spin it’s good to know the authors released an open source package called cleanlab that features algorithms to help you identify bad labels.