Advanced
The library implements a few general tricks to find bad labels, but you can also re-use the components for more elaborate approaches. In this section we hope to demonstrate some more techniques.
Bootstrapping¶
Bootstrapping can be used as a technique to train many similar, but different, models on the same dataset. The predictive difference between these models can be used as a proxy for confidence as well as bad labels.
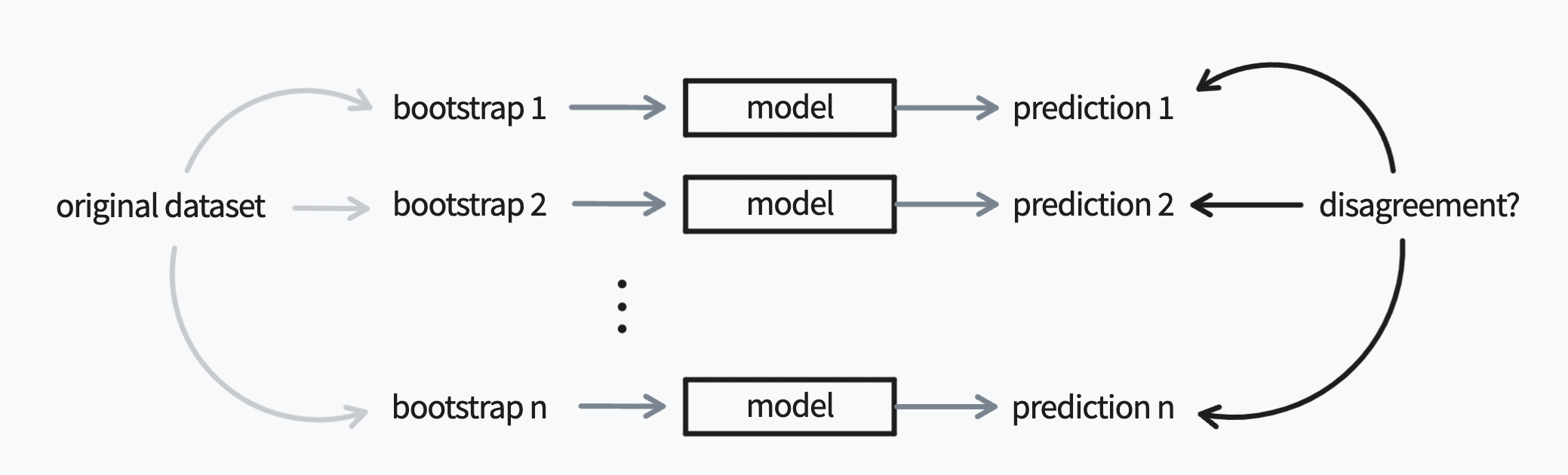
Classification¶
You can use scikit-learn to construct a bootstrapped model for classification which can also be used in this library. You'll want to use the bagging ensemble models for this.
from sklearn.ensemble import BaggingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
# Load in a demo dataset
X, y = make_classification()
# Train a classifier based on bootstrap samples
bc = BaggingClassifier(
base_estimator=LogisticRegression(),
max_samples=0.5,
n_estimators=20
)
bc.fit(X, y)
# You can inspect the trained estimators manually
bc.estimators_
# But you can also predict the probabilities.
bc.predict_proba(X)
These probability values indicate how many internal models predicted a class.
To turn these predicted proba values into a reason for label doubt we can use
the ProbaReason, LongConfidenceReason or the ShortConfidenceReason.
Regression¶
There's a similar trick we might be able to do for regression too!
from sklearn.ensemble import BaggingRegressor
from sklearn.linear_model import LinearRegression
from sklearn.datasets import make_regression
# Load in a demo dataset
X, y = make_regression()
# Train a classifier based on bootstrap samples
bc = BaggingRegressor(
base_estimator=LinearRegression(),
max_samples=0.5,
n_estimators=20
)
bc.fit(X, y)
# You can inspect the trained estimators manually
bc.estimators_
# So you could check the variance between predictions
dev = np.array([e.predict(X) for e in bc.estimators]).std(axis=1)
The deviations in dev could again be interpreted as a proxy for doubt. Because
a doubt ensemble is just an ensemble of callables you can implemented a reason
via:
from doubtlab.ensemble import DoubtEnsemble
threshold = 2
DoubtEnsemble(
wrong_pred=lambda X, y: np.array([e.predict(X) for e in bc.estimators]).std(axis=1) > threshold
)