Feature Selection¶
Maximum Relevance Minimum Redundancy¶
New in version 0.8.0
The Maximum Relevance Minimum Redundancy (MRMR) is an iterative feature selection method commonly used in data science to select a subset of features from a larger feature set. The goal of MRMR is to choose features that have high relevance to the target variable while minimizing redundancy among the already selected features.
MRMR is heavily dependent on the two functions used to determine relevace and redundancy. However, the paper Maximum Relevanceand Minimum Redundancy Feature Selection Methods for a Marketing Machine Learning Platform shows that using f_classif or f_regression as relevance function and Pearson correlation as redundancy function is the best choice for a variety of different problems and in general is a good choice.
Inspired by the Medium article Feature Selection: How To Throw Away 95% of Your Data and Get 95% Accuracy we showcase a practical application using the well known mnist dataset.
Note that although the default scikit-lego MRMR implementation uses redundancy and relevance as defined in Maximum Relevanceand Minimum Redundancy Feature Selection Methods for a Marketing Machine Learning Platform, our implementation offers the possibility of defining custom functions, that may be necessary in different scenarios depending on the data.
We will compare this list of well known filters method:
- F statistical test (ANOVA F-test).
- Mutual information approximation based on sklearn implementation.
Against the default scikit-lego MRMR implementation and a custom MRMR implementation aimed to select features in order to draw a smiling face on the plot showing the minst letters.
MRMR imports
from sklearn.datasets import fetch_openml
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.feature_selection import f_classif, mutual_info_classif
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
from sklego.feature_selection import MaximumRelevanceMinimumRedundancy
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
# Download MNIST dataset using scikit-learn
mnist = fetch_openml("mnist_784", cache=True)
# Assign features and labels
X_pd, y_pd = mnist["data"], mnist["target"].astype(int)
X, y = X_pd.to_numpy(), y_pd.to_numpy()
t_t_s_params = {'test_size': 10000, 'random_state': 42}
X_train, X_test, y_train, y_test = train_test_split(X, y, **t_t_s_params)
X_train = X_train.reshape(60000, 28 * 28)
X_test = X_test.reshape(10000, 28 * 28)
As custom functions, we implemented the smile redundancy and smile relevance.
def smile_relevance(X, y):
rows = 28
cols = 28
smiling_face = np.zeros((rows, cols), dtype=int)
# Set the values for the eyes, nose,
# and mouth with adjusted positions and sizes
# Left eye
smiling_face[10:13, 8:10] = 1
# Right eye
smiling_face[10:13, 18:20] = 1
# Upper part of the mouth
smiling_face[18:20, 10:18] = 1
# Left edge of the open mouth
smiling_face[16:18, 8:10] = 1
# Right edge of the open mouth
smiling_face[16:18, 18:20] = 1
# Add the nose as four pixels one pixel higher
smiling_face[14, 13:15] = 1
smiling_face[27, :] = 1
return smiling_face.reshape(rows * cols,)
def smile_redundancy(X, selected, left):
return np.ones(len(left))
Then we execute the main code part.
K = 38
mrmr = MaximumRelevanceMinimumRedundancy(k=K,
kind="auto",
redundancy_func="p",
relevance_func="f")
mrmr_s = MaximumRelevanceMinimumRedundancy(k=K,
redundancy_func=smile_redundancy,
relevance_func=smile_relevance)
f = f_classif(X_train ,y_train.reshape(60000,))[0]
f_features = np.argsort(np.nan_to_num(f, nan=np.finfo(float).eps))[-K:]
mi = mutual_info_classif(X_train, y_train.reshape(60000,))
mi_features = np.argsort(np.nan_to_num(mi, nan=np.finfo(float).eps))[-K:]
mrmr_features = mrmr.fit(X_train, y_train).selected_features_
mrmr_smile_features = mrmr_s.fit(X_train, y_train).selected_features_
After the execution it is possible to inspect the F1-score for the selected features:
# Define features dictionary
features = {
"f_classif": f_features,
"mutual_info": mi_features,
"mrmr": mrmr_features,
"mrmr_smile": mrmr_smile_features,
}
for name, s_f in features.items():
model = HistGradientBoostingClassifier(random_state=42)
model.fit(X_train[:, s_f], y_train.squeeze())
y_pred = model.predict(X_test[:, s_f])
print(f"Feature selection method: {name}")
print(f"F1 score: {round(f1_score(y_test, y_pred, average="weighted"), 3)}")
Feature selection method: f_classif
F1 score: 0.854
Feature selection method: mutual_info
F1 score: 0.879
Feature selection method: mrmr
F1 score: 0.925
Feature selection method: mrmr_smile
F1 score: 0.849
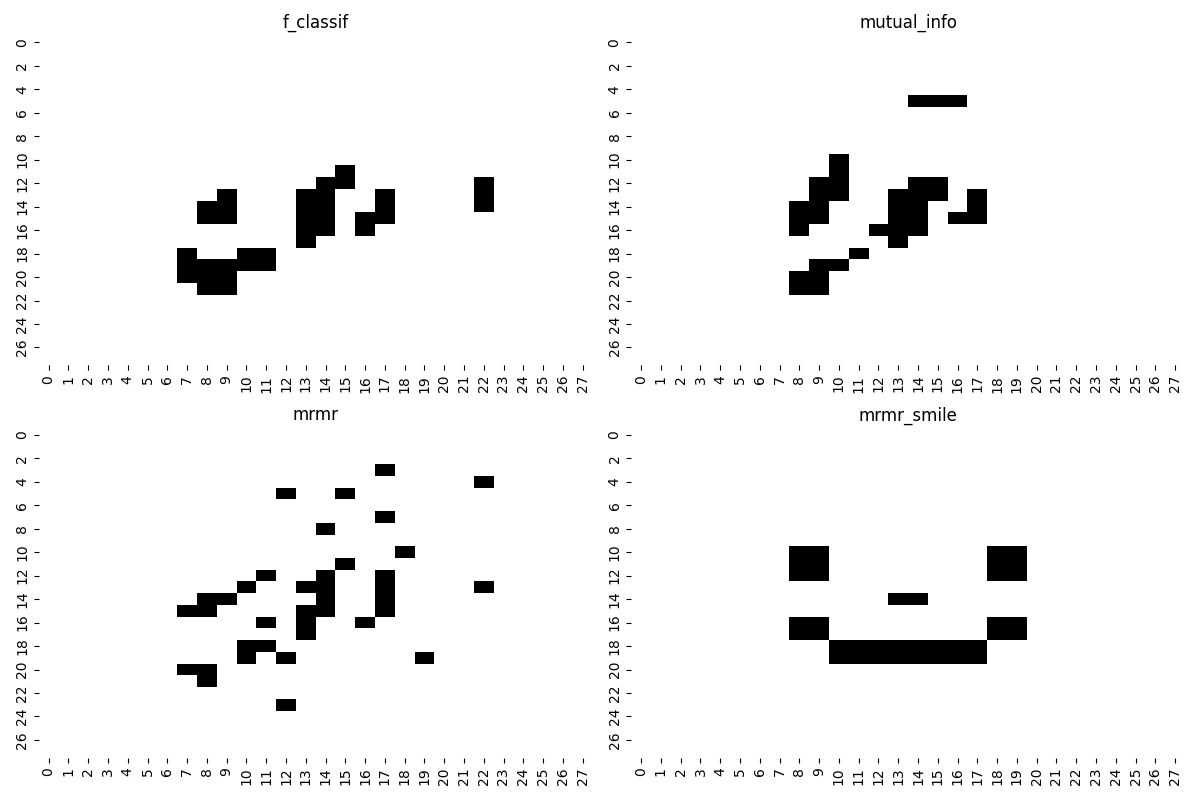
The MRMR feature selection model provides better results compared against the other methods, although the smile technique performs rather good as well.
Finally, we can take a look at the selected features.
MRMR generate plots
# Create figure and axes for the plots
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
# Iterate through the features dictionary and plot the images
for idx, (name, s_f) in enumerate(features.items()):
row = idx // 2
col = idx % 2
a = np.zeros(28 * 28)
a[s_f] = 1
ax = axes[row, col]
plot_= sns.heatmap(a.reshape(28, 28), cmap="binary", ax=ax, cbar=False)
ax.set_title(name)